Take Home Classes On Deepseek
페이지 정보
작성자 Philipp 작성일 25-03-02 01:33 조회 5 댓글 0본문
The DeepSeek crew demonstrated this with their R1-distilled models, which achieve surprisingly robust reasoning performance regardless of being considerably smaller than Free DeepSeek Ai Chat-R1. OpenAI and Microsoft are investigating whether or not the Chinese rival used OpenAI’s API to combine OpenAI’s AI fashions into DeepSeek’s personal models, in accordance with Bloomberg. Either approach, finally, DeepSeek-R1 is a major milestone in open-weight reasoning fashions, and its effectivity at inference time makes it an attention-grabbing various to OpenAI’s o1. However, what stands out is that DeepSeek-R1 is extra environment friendly at inference time. To know this, first you should know that AI mannequin prices can be divided into two classes: training prices (a one-time expenditure to create the model) and runtime "inference" costs - the cost of chatting with the mannequin. This suggests that DeepSeek likely invested extra closely in the coaching course of, while OpenAI could have relied extra on inference-time scaling for o1. But instead of specializing in creating new value-added digital innovations, most firms in the tech sector, even after public backlash concerning the 996 working schedule, have doubled down on squeezing their workforce, chopping costs, and counting on business models driven by worth competitors. 10) impersonates or is designed to impersonate a star, public determine or a person apart from your self with out clearly labelling the content or chatbot as "unofficial" or "parody", unless you could have that individual's express consent.
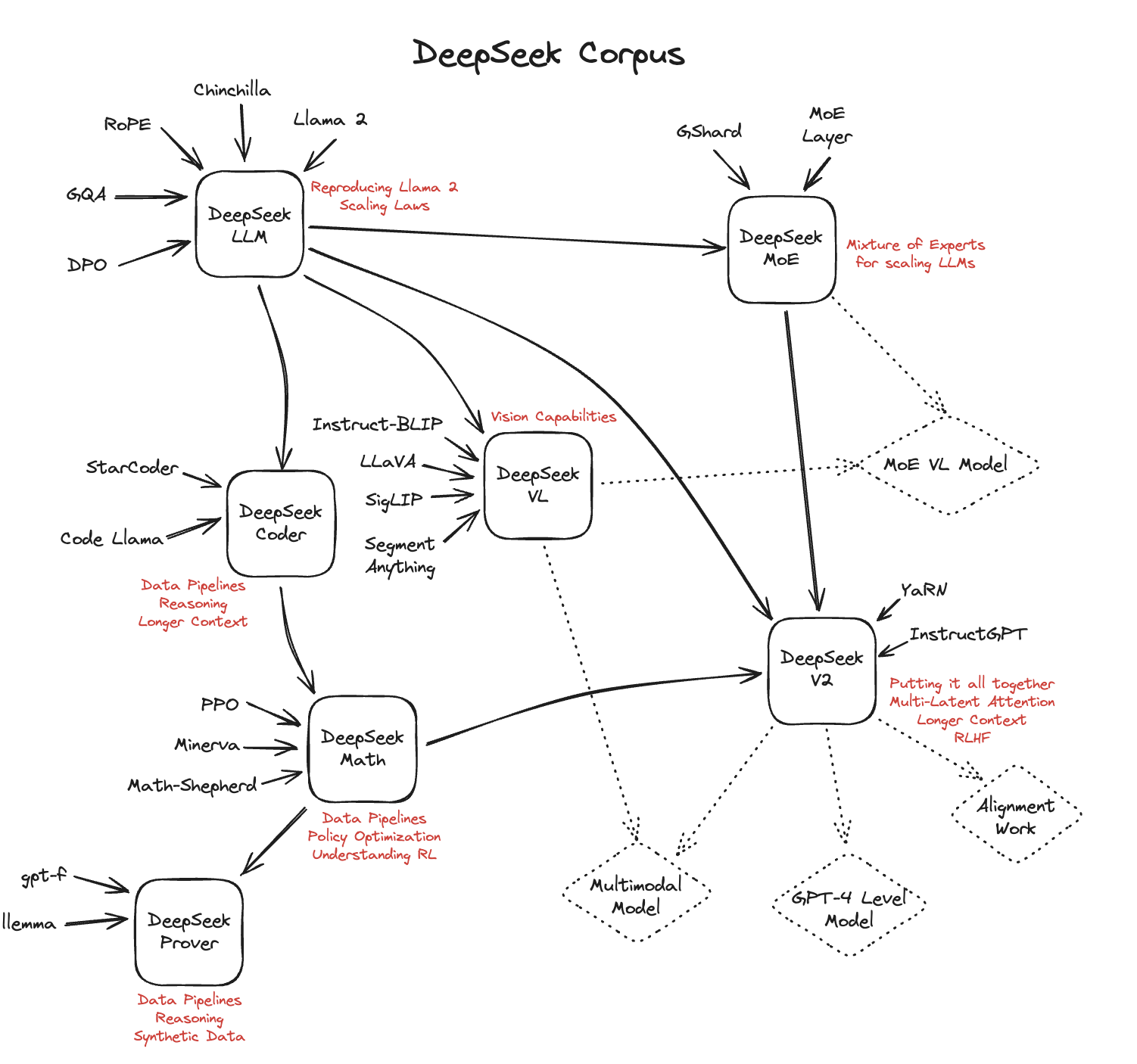 DeepSeek claims to have achieved this by deploying a number of technical strategies that decreased both the quantity of computation time required to prepare its model (referred to as R1) and the amount of reminiscence needed to retailer it. Since the MoE half solely needs to load the parameters of 1 professional, the memory access overhead is minimal, so utilizing fewer SMs will not considerably affect the general performance. FlashMLA’s dynamic scheduling eliminates this overhead by way of precise reminiscence allocation per sequence. One among the largest challenges in theorem proving is figuring out the best sequence of logical steps to resolve a given drawback. The TinyZero repository mentions that a analysis report continues to be work in progress, and I’ll definitely be preserving an eye out for further particulars. 2. Pure RL is attention-grabbing for analysis functions as a result of it offers insights into reasoning as an emergent conduct. These corporations aren’t copying Western advances, they're forging their own path, constructed on unbiased research and improvement. Shortcut studying refers to the standard strategy in instruction wonderful-tuning, where fashions are educated utilizing solely appropriate solution paths. This aligns with the idea that RL alone may not be enough to induce robust reasoning skills in models of this scale, whereas SFT on high-high quality reasoning information generally is a more effective technique when working with small fashions.
DeepSeek claims to have achieved this by deploying a number of technical strategies that decreased both the quantity of computation time required to prepare its model (referred to as R1) and the amount of reminiscence needed to retailer it. Since the MoE half solely needs to load the parameters of 1 professional, the memory access overhead is minimal, so utilizing fewer SMs will not considerably affect the general performance. FlashMLA’s dynamic scheduling eliminates this overhead by way of precise reminiscence allocation per sequence. One among the largest challenges in theorem proving is figuring out the best sequence of logical steps to resolve a given drawback. The TinyZero repository mentions that a analysis report continues to be work in progress, and I’ll definitely be preserving an eye out for further particulars. 2. Pure RL is attention-grabbing for analysis functions as a result of it offers insights into reasoning as an emergent conduct. These corporations aren’t copying Western advances, they're forging their own path, constructed on unbiased research and improvement. Shortcut studying refers to the standard strategy in instruction wonderful-tuning, where fashions are educated utilizing solely appropriate solution paths. This aligns with the idea that RL alone may not be enough to induce robust reasoning skills in models of this scale, whereas SFT on high-high quality reasoning information generally is a more effective technique when working with small fashions.
Surprisingly, even at just 3B parameters, TinyZero exhibits some emergent self-verification talents, which supports the concept that reasoning can emerge by means of pure RL, even in small fashions. RL, similar to how DeepSeek-R1 was developed. 6 million training cost, but they probably conflated DeepSeek-V3 (the bottom mannequin released in December last 12 months) and DeepSeek-R1. According to their benchmarks, Sky-T1 performs roughly on par with o1, which is impressive given its low training price. While each approaches replicate strategies from DeepSeek-R1, one specializing in pure RL (TinyZero) and the opposite on pure SFT (Sky-T1), it would be fascinating to discover how these concepts can be prolonged additional. While Sky-T1 targeted on model distillation, I also got here across some fascinating work in the "pure RL" area. Interestingly, just some days earlier than DeepSeek-R1 was launched, I came across an article about Sky-T1, an interesting undertaking the place a small team trained an open-weight 32B model using solely 17K SFT samples. As an illustration, distillation all the time relies on an current, stronger model to generate the supervised effective-tuning (SFT) data. This example highlights that whereas massive-scale coaching remains expensive, smaller, targeted fantastic-tuning efforts can nonetheless yield spectacular results at a fraction of the associated fee. Massive Training Data: Trained from scratch on 2T tokens, together with 87% code and 13% linguistic data in both English and Chinese languages.
The expertise hired by DeepSeek have been new or latest graduates and doctoral college students from high home Chinese universities. While its breakthroughs are no doubt impressive, the latest cyberattack raises questions on the safety of rising know-how. Due to concerns about massive language fashions getting used to generate misleading, biased, or abusive language at scale, we're only releasing a much smaller model of GPT-2 together with sampling code(opens in a brand new window). Geopolitical considerations. Being based mostly in China, DeepSeek challenges U.S. The largest mistake U.S. This gap is additional widened by U.S. DeepSeek is emblematic of a broader transformation in China’s AI ecosystem, which is producing world-class fashions and systematically narrowing the hole with the United States. This comparability offers some further insights into whether or not pure RL alone can induce reasoning capabilities in models a lot smaller than DeepSeek-R1-Zero. There are three fundamental insights policymakers ought to take from the current news. The too-on-line finance dorks are at it once more. But there are two key issues which make DeepSeek v3 R1 completely different. Amid the noise, one factor is obvious: DeepSeek’s breakthrough is a wake-up call that China’s AI capabilities are advancing faster than Western conventional knowledge has acknowledged. One notable example is TinyZero, a 3B parameter model that replicates the DeepSeek-R1-Zero approach (side be aware: it prices lower than $30 to prepare).
In the event you cherished this information and also you would want to acquire more info relating to Deepseek Online chat online i implore you to visit the web site.
- 이전글 تعرفي على أهم 50 مدرب، ومدربة لياقة بدنية في 2025
- 다음글 W.I.L. Offshore News Digest For Week Of November 10, 2025
댓글목록 0
등록된 댓글이 없습니다.