Vital Pieces Of Deepseek
페이지 정보
작성자 Shelton 작성일 25-02-01 07:00 조회 14 댓글 0본문
 The 67B Base mannequin demonstrates a qualitative leap within the capabilities of DeepSeek LLMs, exhibiting their proficiency throughout a wide range of functions. DeepSeek AI has decided to open-supply each the 7 billion and 67 billion parameter versions of its fashions, together with the base and chat variants, to foster widespread AI research and commercial purposes. By open-sourcing its models, code, and knowledge, DeepSeek LLM hopes to promote widespread AI research and business applications. From the outset, it was free for commercial use and fully open-source. But did you know you may run self-hosted AI models totally free on your own hardware? Free for commercial use and fully open-source. The rival firm said the former employee possessed quantitative strategy codes which can be considered "core commercial secrets" and sought 5 million Yuan in compensation for anti-competitive practices. The models can be found on GitHub and Hugging Face, together with the code and information used for coaching and analysis. Click cancel if it asks you to sign up to GitHub. It's educated on licensed knowledge from GitHub, Git commits, GitHub issues, and Jupyter notebooks. Alibaba’s Qwen mannequin is the world’s finest open weight code model (Import AI 392) - and so they achieved this by means of a mixture of algorithmic insights and access to knowledge (5.5 trillion top quality code/math ones).
The 67B Base mannequin demonstrates a qualitative leap within the capabilities of DeepSeek LLMs, exhibiting their proficiency throughout a wide range of functions. DeepSeek AI has decided to open-supply each the 7 billion and 67 billion parameter versions of its fashions, together with the base and chat variants, to foster widespread AI research and commercial purposes. By open-sourcing its models, code, and knowledge, DeepSeek LLM hopes to promote widespread AI research and business applications. From the outset, it was free for commercial use and fully open-source. But did you know you may run self-hosted AI models totally free on your own hardware? Free for commercial use and fully open-source. The rival firm said the former employee possessed quantitative strategy codes which can be considered "core commercial secrets" and sought 5 million Yuan in compensation for anti-competitive practices. The models can be found on GitHub and Hugging Face, together with the code and information used for coaching and analysis. Click cancel if it asks you to sign up to GitHub. It's educated on licensed knowledge from GitHub, Git commits, GitHub issues, and Jupyter notebooks. Alibaba’s Qwen mannequin is the world’s finest open weight code model (Import AI 392) - and so they achieved this by means of a mixture of algorithmic insights and access to knowledge (5.5 trillion top quality code/math ones).
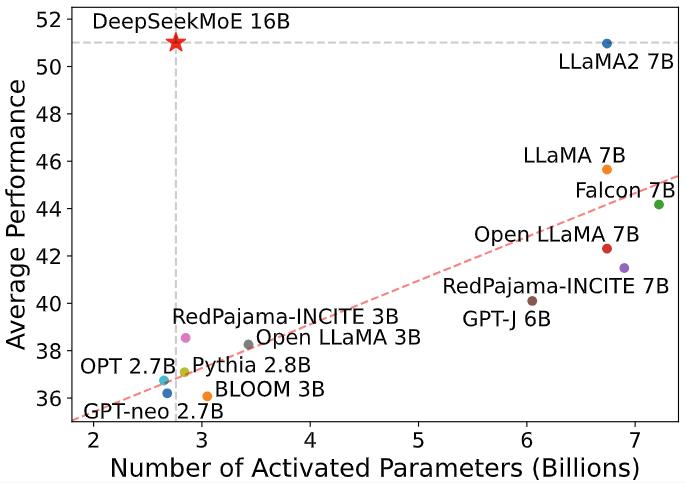 Whether you're a knowledge scientist, enterprise chief, or tech enthusiast, DeepSeek R1 is your final instrument to unlock the true potential of your knowledge. DeepSeek LLM 67B Chat had already demonstrated vital performance, approaching that of GPT-4. Another notable achievement of the DeepSeek LLM household is the LLM 7B Chat and 67B Chat fashions, which are specialised for conversational tasks. The LLM 67B Chat model achieved an impressive 73.78% pass price on the HumanEval coding benchmark, surpassing fashions of comparable size. The DeepSeek LLM family consists of four fashions: DeepSeek LLM 7B Base, DeepSeek LLM 67B Base, DeepSeek LLM 7B Chat, and DeepSeek 67B Chat. One of the primary options that distinguishes the DeepSeek LLM household from different LLMs is the superior performance of the 67B Base model, which outperforms the Llama2 70B Base model in a number of domains, resembling reasoning, coding, mathematics, and Chinese comprehension. Later, on November 29, 2023, DeepSeek launched DeepSeek LLM, described as the "next frontier of open-supply LLMs," scaled as much as 67B parameters. 610 opened Jan 29, 2025 by Imadnajam Loading… Despite being in improvement for a couple of years, DeepSeek seems to have arrived almost overnight after the discharge of its R1 mannequin on Jan 20 took the AI world by storm, primarily because it offers performance that competes with ChatGPT-o1 with out charging you to make use of it.
Whether you're a knowledge scientist, enterprise chief, or tech enthusiast, DeepSeek R1 is your final instrument to unlock the true potential of your knowledge. DeepSeek LLM 67B Chat had already demonstrated vital performance, approaching that of GPT-4. Another notable achievement of the DeepSeek LLM household is the LLM 7B Chat and 67B Chat fashions, which are specialised for conversational tasks. The LLM 67B Chat model achieved an impressive 73.78% pass price on the HumanEval coding benchmark, surpassing fashions of comparable size. The DeepSeek LLM family consists of four fashions: DeepSeek LLM 7B Base, DeepSeek LLM 67B Base, DeepSeek LLM 7B Chat, and DeepSeek 67B Chat. One of the primary options that distinguishes the DeepSeek LLM household from different LLMs is the superior performance of the 67B Base model, which outperforms the Llama2 70B Base model in a number of domains, resembling reasoning, coding, mathematics, and Chinese comprehension. Later, on November 29, 2023, DeepSeek launched DeepSeek LLM, described as the "next frontier of open-supply LLMs," scaled as much as 67B parameters. 610 opened Jan 29, 2025 by Imadnajam Loading… Despite being in improvement for a couple of years, DeepSeek seems to have arrived almost overnight after the discharge of its R1 mannequin on Jan 20 took the AI world by storm, primarily because it offers performance that competes with ChatGPT-o1 with out charging you to make use of it.
We're excited to announce the discharge of SGLang v0.3, which brings vital performance enhancements and expanded support for novel mannequin architectures. The LLM was trained on a large dataset of two trillion tokens in both English and Chinese, employing architectures such as LLaMA and Grouped-Query Attention. While particular languages supported should not listed, DeepSeek Coder is skilled on an enormous dataset comprising 87% code from multiple sources, suggesting broad language support. This time builders upgraded the earlier version of their Coder and now DeepSeek-Coder-V2 supports 338 languages and 128K context length. Its 128K token context window means it can course of and understand very lengthy paperwork. With this model, DeepSeek AI showed it might effectively course of high-resolution photographs (1024x1024) within a fixed token budget, all whereas retaining computational overhead low. By implementing these methods, DeepSeekMoE enhances the efficiency of the model, permitting it to perform higher than different MoE models, especially when dealing with larger datasets. Their revolutionary approaches to consideration mechanisms and the Mixture-of-Experts (MoE) approach have led to impressive effectivity good points. This led the DeepSeek AI staff to innovate additional and develop their own approaches to unravel these current problems.
It pushes the boundaries of AI by fixing complicated mathematical problems akin to these within the International Mathematical Olympiad (IMO). Feng, deepseek ai china Rebecca. "Top Chinese Quant Fund Apologizes to Investors After Recent Struggles". DeepSeek AI, a Chinese AI startup, has announced the launch of the DeepSeek LLM family, a set of open-supply large language models (LLMs) that achieve outstanding leads to varied language duties. "Our results constantly reveal the efficacy of LLMs in proposing high-health variants. Though Llama 3 70B (and even the smaller 8B mannequin) is ok for 99% of individuals and duties, generally you simply need the very best, so I like having the choice either to only shortly answer my query or even use it along facet other LLMs to rapidly get choices for a solution. Aider lets you pair program with LLMs to edit code in your local git repository Start a brand new undertaking or work with an present git repo.
- 이전글 Discovering the Perfect Scam Verification Platform: Casino79 for Your Gambling Site Experience
- 다음글 Enhancing Korean Sports Betting Safety with Sureman’s Scam Verification Platform
댓글목록 0
등록된 댓글이 없습니다.