Best Deepseek Android Apps
페이지 정보
작성자 Carrol 작성일 25-02-02 12:40 조회 3 댓글 0본문
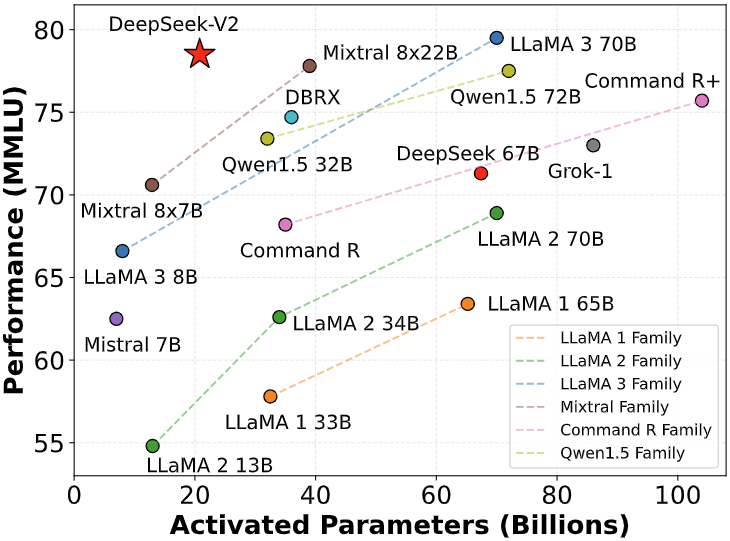 deepseek ai china, a company based in China which goals to "unravel the thriller of AGI with curiosity," has released DeepSeek LLM, a 67 billion parameter model trained meticulously from scratch on a dataset consisting of two trillion tokens. The reward model is trained from the DeepSeek-V3 SFT checkpoints. 0.1. We set the utmost sequence size to 4K during pre-coaching, and pre-prepare DeepSeek-V3 on 14.8T tokens. POSTSUPERSCRIPT. During training, each single sequence is packed from a number of samples. Compared with the sequence-clever auxiliary loss, batch-wise balancing imposes a extra versatile constraint, because it doesn't enforce in-domain stability on each sequence. To be specific, in our experiments with 1B MoE models, the validation losses are: 2.258 (utilizing a sequence-wise auxiliary loss), 2.253 (utilizing the auxiliary-loss-free technique), and 2.253 (using a batch-sensible auxiliary loss). The important thing distinction between auxiliary-loss-free balancing and sequence-wise auxiliary loss lies of their balancing scope: batch-wise versus sequence-wise. On prime of these two baseline fashions, holding the coaching data and the opposite architectures the same, we remove all auxiliary losses and introduce the auxiliary-loss-free balancing technique for comparison. To be specific, we validate the MTP technique on high of two baseline fashions across different scales.
deepseek ai china, a company based in China which goals to "unravel the thriller of AGI with curiosity," has released DeepSeek LLM, a 67 billion parameter model trained meticulously from scratch on a dataset consisting of two trillion tokens. The reward model is trained from the DeepSeek-V3 SFT checkpoints. 0.1. We set the utmost sequence size to 4K during pre-coaching, and pre-prepare DeepSeek-V3 on 14.8T tokens. POSTSUPERSCRIPT. During training, each single sequence is packed from a number of samples. Compared with the sequence-clever auxiliary loss, batch-wise balancing imposes a extra versatile constraint, because it doesn't enforce in-domain stability on each sequence. To be specific, in our experiments with 1B MoE models, the validation losses are: 2.258 (utilizing a sequence-wise auxiliary loss), 2.253 (utilizing the auxiliary-loss-free technique), and 2.253 (using a batch-sensible auxiliary loss). The important thing distinction between auxiliary-loss-free balancing and sequence-wise auxiliary loss lies of their balancing scope: batch-wise versus sequence-wise. On prime of these two baseline fashions, holding the coaching data and the opposite architectures the same, we remove all auxiliary losses and introduce the auxiliary-loss-free balancing technique for comparison. To be specific, we validate the MTP technique on high of two baseline fashions across different scales.
From the desk, we can observe that the auxiliary-loss-free technique constantly achieves better model efficiency on many of the analysis benchmarks. With this unified interface, computation models can simply accomplish operations akin to read, write, multicast, and cut back across the whole IB-NVLink-unified domain via submitting communication requests based mostly on simple primitives. Moreover, utilizing SMs for communication leads to important inefficiencies, as tensor cores stay solely -utilized. Higher FP8 GEMM Accumulation Precision in Tensor Cores. Combined with the fusion of FP8 format conversion and TMA entry, this enhancement will considerably streamline the quantization workflow. To handle this inefficiency, we recommend that future chips integrate FP8 cast and TMA (Tensor Memory Accelerator) access right into a single fused operation, so quantization can be accomplished throughout the switch of activations from world memory to shared reminiscence, avoiding frequent reminiscence reads and writes. In case you have some huge cash and you've got loads of GPUs, you can go to the perfect individuals and say, "Hey, why would you go work at a company that really cannot provde the infrastructure you want to do the work it is advisable do? Additionally, there’s a couple of twofold hole in information effectivity, which means we'd like twice the coaching knowledge and computing power to reach comparable outcomes.
In the existing process, we need to read 128 BF16 activation values (the output of the earlier computation) from HBM (High Bandwidth Memory) for quantization, and the quantized FP8 values are then written again to HBM, only to be learn once more for MMA. The mix of low-bit quantization and hardware optimizations such the sliding window design help ship the conduct of a larger model inside the memory footprint of a compact mannequin. To scale back reminiscence operations, we advocate future chips to enable direct transposed reads of matrices from shared memory earlier than MMA operation, for these precisions required in each coaching and inference. Note that during inference, we straight discard the MTP module, so the inference costs of the compared fashions are exactly the same. The evaluation outcomes display that the distilled smaller dense fashions carry out exceptionally nicely on benchmarks. The base model of DeepSeek-V3 is pretrained on a multilingual corpus with English and Chinese constituting the majority, so we consider its efficiency on a series of benchmarks primarily in English and Chinese, as well as on a multilingual benchmark. We release the DeepSeek LLM 7B/67B, together with each base and chat fashions, to the public. Mistral solely put out their 7B and 8x7B models, but their Mistral Medium mannequin is effectively closed supply, identical to OpenAI’s.
POSTSUPERSCRIPT until the mannequin consumes 10T coaching tokens. 0.Three for the primary 10T tokens, and to 0.1 for the remaining 4.8T tokens. Pretrained on 2 Trillion tokens over greater than 80 programming languages. Under our coaching framework and infrastructures, coaching DeepSeek-V3 on every trillion tokens requires solely 180K H800 GPU hours, which is far cheaper than training 72B or 405B dense models. Evaluating giant language models skilled on code. Facebook has launched Sapiens, a household of pc vision fashions that set new state-of-the-art scores on tasks including "2D pose estimation, body-half segmentation, depth estimation, and floor regular prediction". D is about to 1, i.e., in addition to the exact next token, every token will predict one additional token. Under this configuration, DeepSeek-V3 includes 671B whole parameters, of which 37B are activated for each token. Through this two-section extension coaching, DeepSeek-V3 is capable of dealing with inputs up to 128K in size whereas sustaining strong efficiency.
If you are you looking for more about ديب سيك check out our website.
댓글목록 0
등록된 댓글이 없습니다.