The World's Most Unusual Deepseek
페이지 정보
작성자 Tawnya 작성일 25-03-07 09:23 조회 10 댓글 0본문
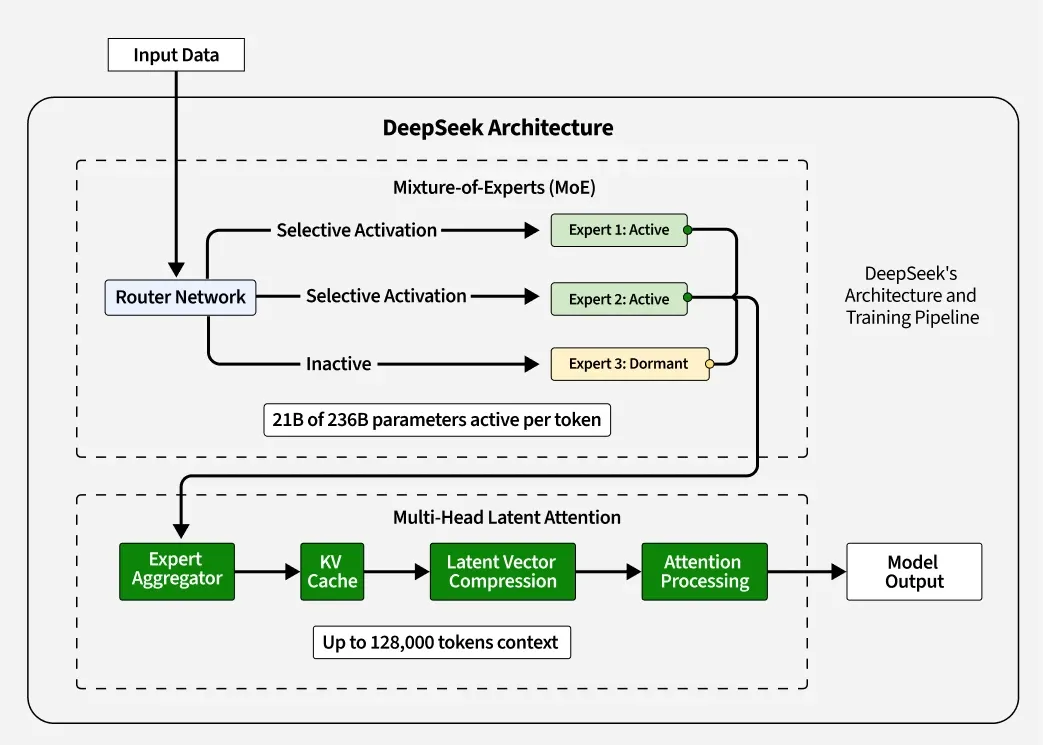 DeepSeek v3 does so by combining a number of different improvements, every of which I will discuss in turn. Gradient descent will then reinforce the tendency to pick these consultants. This will converge faster than gradient ascent on the log-chance. This naive value can be brought down e.g. by speculative sampling, however it provides an honest ballpark estimate. This cuts down the scale of the KV cache by a factor equal to the group dimension we’ve chosen. This growing panic has culminated in a wholesale rout of tech names around the globe which has since reworked into a full-blown DeepSink rout knowledgeable, sending S&P futures down as much as 3% and Nasdaq futures down 5%, earlier than a modest bounce. Running DeepSeek on Windows is a reliable option, particularly with rising concerns about privateness. The earnings report from Nvidia, which has turn out to be a marquee quarterly occasion for market contributors, could help revive optimism in regards to the AI commerce that has fueled a inventory market rally in recent times or inject contemporary concerns concerning the sustainability of those features. Additionally, there are considerations about hidden code throughout the models that could transmit person data to Chinese entities, elevating vital privateness and safety points.
DeepSeek v3 does so by combining a number of different improvements, every of which I will discuss in turn. Gradient descent will then reinforce the tendency to pick these consultants. This will converge faster than gradient ascent on the log-chance. This naive value can be brought down e.g. by speculative sampling, however it provides an honest ballpark estimate. This cuts down the scale of the KV cache by a factor equal to the group dimension we’ve chosen. This growing panic has culminated in a wholesale rout of tech names around the globe which has since reworked into a full-blown DeepSink rout knowledgeable, sending S&P futures down as much as 3% and Nasdaq futures down 5%, earlier than a modest bounce. Running DeepSeek on Windows is a reliable option, particularly with rising concerns about privateness. The earnings report from Nvidia, which has turn out to be a marquee quarterly occasion for market contributors, could help revive optimism in regards to the AI commerce that has fueled a inventory market rally in recent times or inject contemporary concerns concerning the sustainability of those features. Additionally, there are considerations about hidden code throughout the models that could transmit person data to Chinese entities, elevating vital privateness and safety points.
 On 27 January 2025, DeepSeek restricted its new person registration to phone numbers from mainland China, electronic mail addresses, or Google account logins, after a "massive-scale" cyberattack disrupted the right functioning of its servers. In China, the "better to be the head of a hen than the tail of a phoenix" 宁当鸡头,不做凤尾 mindset discourages acquisitions, limiting exit options and ecosystem dynamism. Expert routing algorithms work as follows: as soon as we exit the attention block of any layer, now we have a residual stream vector that is the output. When you see the method, it’s immediately apparent that it cannot be any worse than grouped-question attention and it’s additionally more likely to be considerably better. The technical report notes this achieves better efficiency than counting on an auxiliary loss whereas nonetheless making certain acceptable load balance. This can imply these specialists will get almost all the gradient indicators during updates and turn into better whereas other specialists lag behind, and so the opposite experts will proceed not being picked, producing a optimistic feedback loop that ends in different experts by no means getting chosen or skilled.
On 27 January 2025, DeepSeek restricted its new person registration to phone numbers from mainland China, electronic mail addresses, or Google account logins, after a "massive-scale" cyberattack disrupted the right functioning of its servers. In China, the "better to be the head of a hen than the tail of a phoenix" 宁当鸡头,不做凤尾 mindset discourages acquisitions, limiting exit options and ecosystem dynamism. Expert routing algorithms work as follows: as soon as we exit the attention block of any layer, now we have a residual stream vector that is the output. When you see the method, it’s immediately apparent that it cannot be any worse than grouped-question attention and it’s additionally more likely to be considerably better. The technical report notes this achieves better efficiency than counting on an auxiliary loss whereas nonetheless making certain acceptable load balance. This can imply these specialists will get almost all the gradient indicators during updates and turn into better whereas other specialists lag behind, and so the opposite experts will proceed not being picked, producing a optimistic feedback loop that ends in different experts by no means getting chosen or skilled.
These bias terms aren't up to date by gradient descent however are instead adjusted all through training to ensure load stability: if a particular knowledgeable will not be getting as many hits as we expect it should, then we will slightly bump up its bias time period by a hard and fast small amount every gradient step till it does. Multi-head latent consideration is based on the clever commentary that this is definitely not true, because we will merge the matrix multiplications that may compute the upscaled key and worth vectors from their latents with the question and submit-attention projections, respectively. Resulting from its differences from customary consideration mechanisms, existing open-source libraries haven't absolutely optimized this operation. Each expert has a corresponding professional vector of the identical dimension, and we decide which experts will change into activated by looking at which of them have the highest inside merchandise with the current residual stream. This causes gradient descent optimization methods to behave poorly in MoE training, usually resulting in "routing collapse", the place the model gets stuck all the time activating the same few experts for each token as an alternative of spreading its knowledge and computation round all of the obtainable experts. To get an intuition for routing collapse, consider trying to practice a mannequin such as GPT-four with 16 specialists in total and a pair of specialists energetic per token.
However, the Free DeepSeek Chat v3 technical report notes that such an auxiliary loss hurts model performance even if it ensures balanced routing. To see why, consider that any large language mannequin possible has a small amount of knowledge that it makes use of so much, whereas it has loads of information that it uses quite infrequently. A well-liked technique for avoiding routing collapse is to power "balanced routing", i.e. the property that every professional is activated roughly an equal number of times over a sufficiently large batch, by including to the training loss a time period measuring how imbalanced the skilled routing was in a specific batch. This term known as an "auxiliary loss" and it makes intuitive sense that introducing it pushes the model towards balanced routing. And this isn't even mentioning the work within Deepmind of making the Alpha model sequence and making an attempt to incorporate these into the massive Language world. However, when our neural community is so discontinuous in its behavior, even the high dimensionality of the issue house may not save us from failure. This often works wonderful within the very excessive dimensional optimization problems encountered in neural community training. Again, just to emphasise this point, all of the selections Free DeepSeek Ai Chat made in the design of this mannequin solely make sense if you're constrained to the H800; if DeepSeek had access to H100s, they most likely would have used a bigger coaching cluster with much fewer optimizations specifically centered on overcoming the lack of bandwidth.
댓글목록 0
등록된 댓글이 없습니다.