The Pain Of Deepseek
페이지 정보
작성자 Adela 작성일 25-03-08 03:21 조회 6 댓글 0본문
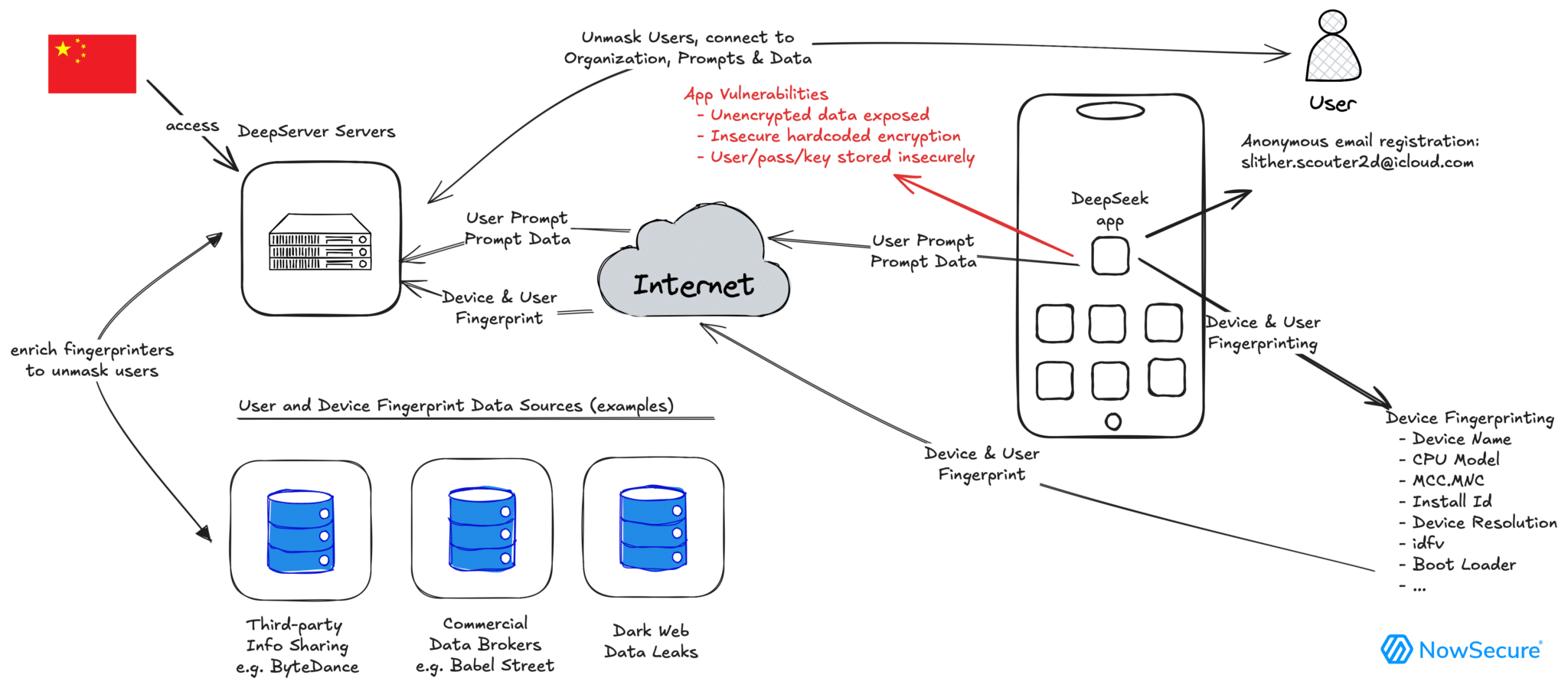 By applying superior analytics strategies, Free DeepSeek r1 helps businesses uncover patterns, traits, and insights that may inform strategic selections and DeepSeek Chat drive innovation. Having advantages that may be scaled to arbitrarily large values means the whole objective perform can explode to arbitrarily large values, which suggests the reinforcement studying can rapidly move very far from the outdated version of the mannequin. Despite its massive dimension, Deepseek Online chat v3 maintains efficient inference capabilities by modern architecture design. It’s not a new breakthrough in capabilities. We also assume governments ought to consider expanding or commencing initiatives to extra systematically monitor the societal impact and diffusion of AI applied sciences, and to measure the progression within the capabilities of such techniques. If you actually like graphs as much as I do, you can consider this as a floor the place, πθ deviates from πref we get excessive values for our KL Divergence. Let’s graph out this DKL perform for a few completely different values of πref(oi|q) and πθ(oi|q) and see what we get. If the benefit is unfavourable (the reward of a selected output is far worse than all different outputs), and if the new mannequin is much, way more confident about that output, that will lead to a really large unfavorable quantity which may pass, unclipped, by means of the minimal operate.
By applying superior analytics strategies, Free DeepSeek r1 helps businesses uncover patterns, traits, and insights that may inform strategic selections and DeepSeek Chat drive innovation. Having advantages that may be scaled to arbitrarily large values means the whole objective perform can explode to arbitrarily large values, which suggests the reinforcement studying can rapidly move very far from the outdated version of the mannequin. Despite its massive dimension, Deepseek Online chat v3 maintains efficient inference capabilities by modern architecture design. It’s not a new breakthrough in capabilities. We also assume governments ought to consider expanding or commencing initiatives to extra systematically monitor the societal impact and diffusion of AI applied sciences, and to measure the progression within the capabilities of such techniques. If you actually like graphs as much as I do, you can consider this as a floor the place, πθ deviates from πref we get excessive values for our KL Divergence. Let’s graph out this DKL perform for a few completely different values of πref(oi|q) and πθ(oi|q) and see what we get. If the benefit is unfavourable (the reward of a selected output is far worse than all different outputs), and if the new mannequin is much, way more confident about that output, that will lead to a really large unfavorable quantity which may pass, unclipped, by means of the minimal operate.
 If the benefit is high, and the brand new mannequin is far more confident about that output than the previous mannequin, then that is allowed to develop, however may be clipped relying on how massive "ε" is. Here "ε" is a few parameter which knowledge scientists can tweak to manage how a lot, or how little, exploration away from πθold is constrained. HaiScale Distributed Data Parallel (DDP): Parallel coaching library that implements numerous types of parallelism equivalent to Data Parallelism (DP), Pipeline Parallelism (PP), Tensor Parallelism (TP), Experts Parallelism (EP), Fully Sharded Data Parallel (FSDP) and Zero Redundancy Optimizer (ZeRO). Thus, training πθ based on the output from πθold becomes less and less affordable as we progress through the coaching course of. By using this strategy, we will reinforce our mannequin quite a few occasions on the same knowledge throughout the greater reinforcement studying process. The Financial Times reported that it was cheaper than its friends with a worth of two RMB for each million output tokens. Here, I wrote out the expression for KL divergence and gave it a few values of what our reference model output, and confirmed what the divergence could be for multiple values of πθ output. We’re saying "this is a particularly good or unhealthy output, based on how it performs relative to all different outputs.
If the benefit is high, and the brand new mannequin is far more confident about that output than the previous mannequin, then that is allowed to develop, however may be clipped relying on how massive "ε" is. Here "ε" is a few parameter which knowledge scientists can tweak to manage how a lot, or how little, exploration away from πθold is constrained. HaiScale Distributed Data Parallel (DDP): Parallel coaching library that implements numerous types of parallelism equivalent to Data Parallelism (DP), Pipeline Parallelism (PP), Tensor Parallelism (TP), Experts Parallelism (EP), Fully Sharded Data Parallel (FSDP) and Zero Redundancy Optimizer (ZeRO). Thus, training πθ based on the output from πθold becomes less and less affordable as we progress through the coaching course of. By using this strategy, we will reinforce our mannequin quite a few occasions on the same knowledge throughout the greater reinforcement studying process. The Financial Times reported that it was cheaper than its friends with a worth of two RMB for each million output tokens. Here, I wrote out the expression for KL divergence and gave it a few values of what our reference model output, and confirmed what the divergence could be for multiple values of πθ output. We’re saying "this is a particularly good or unhealthy output, based on how it performs relative to all different outputs.
Thus, if the brand new mannequin is more assured about unhealthy solutions than the previous model used to generate those solutions, the objective function becomes unfavourable, which is used to prepare the mannequin to closely de-incentivise such outputs. This process can happen iteratively, for a similar outputs generated by the old model, over numerous iterations. GRPO iterations. So, it’s the parameters we used once we first started the GRPO course of. That is the majority of the GRPO advantage operate, from a conceptual potential. If the chance of the old model is much increased than the brand new model, then the results of this ratio shall be near zero, thus scaling down the advantage of the example. This might make some sense (a response was higher, and the mannequin was very assured in it, that’s probably an uncharacteristically good answer), but a central thought is that we’re optimizing πθ based mostly on the output of πθold , and thus we shouldn’t deviate too far from πθold . If the new and old mannequin output the same output, then they’re most likely fairly comparable, and thus we train based on the full drive of the benefit for that example. If an advantage is high, for a particular output, and the previous mannequin was rather more positive about that output than the brand new model, then the reward function is hardly affected.
All the GRPO operate as a property referred to as "differentiability". GRPO at all. So, πθ is the present mannequin being trained, πθold is from the last round and was used to generate the current batch of outputs, and πref represents the mannequin before we did any reinforcement studying (essentially, this mannequin was solely educated with the normal supervised studying strategy). We are able to get the current model, πθ , to predict how probably it thinks a sure output is, and we are able to compare that to the probabilities πθold had when outputting the reply we’re coaching on. If this number is large, for a given output, the coaching strategy heavily reinforces that output throughout the model. Because the new mannequin is constrained to be just like the model used to generate the output, the output should be reasonably relevent in training the new mannequin. As you may see, as πθ deviates from whatever the reference mannequin output, the KL divergence will increase.
If you loved this report and you would like to receive extra data relating to Deepseek AI Online chat kindly check out our own page.
댓글목록 0
등록된 댓글이 없습니다.