Stable Reasons To Keep away from Deepseek Chatgpt
페이지 정보
작성자 Dale 작성일 25-03-23 02:42 조회 3 댓글 0본문
 I already laid out last fall how every aspect of Meta’s enterprise advantages from AI; a giant barrier to realizing that imaginative and prescient is the cost of inference, which implies that dramatically cheaper inference - and dramatically cheaper training, given the necessity for Meta to remain on the leading edge - makes that imaginative and prescient way more achievable. AI trade, and the advantages or not of open source for innovation. Using GroqCloud with Open WebUI is feasible due to an OpenAI-compatible API that Groq supplies. Moreover, the method was a simple one: as a substitute of attempting to evaluate step-by-step (course of supervision), or doing a search of all doable answers (a la AlphaGo), DeepSeek encouraged the model to try several different answers at a time and then graded them in accordance with the 2 reward capabilities. Special due to those that assist make my writing possible and sustainable. OpenAI doesn't have some sort of special sauce that can’t be replicated.
I already laid out last fall how every aspect of Meta’s enterprise advantages from AI; a giant barrier to realizing that imaginative and prescient is the cost of inference, which implies that dramatically cheaper inference - and dramatically cheaper training, given the necessity for Meta to remain on the leading edge - makes that imaginative and prescient way more achievable. AI trade, and the advantages or not of open source for innovation. Using GroqCloud with Open WebUI is feasible due to an OpenAI-compatible API that Groq supplies. Moreover, the method was a simple one: as a substitute of attempting to evaluate step-by-step (course of supervision), or doing a search of all doable answers (a la AlphaGo), DeepSeek encouraged the model to try several different answers at a time and then graded them in accordance with the 2 reward capabilities. Special due to those that assist make my writing possible and sustainable. OpenAI doesn't have some sort of special sauce that can’t be replicated.
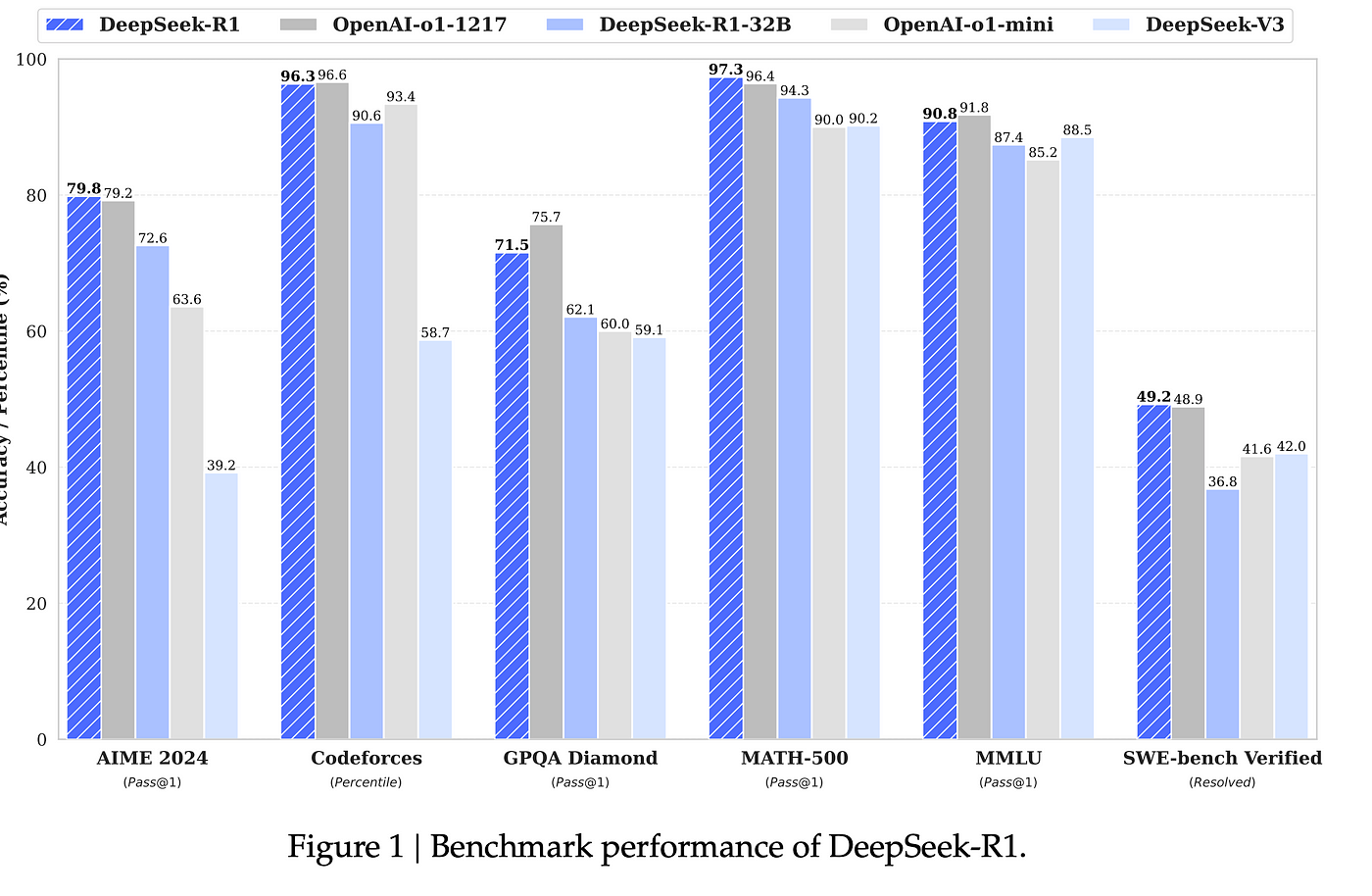
Because some controversial instances that drew public criticism for their low punishments have been withdrawn from China Judgments Online, there are issues about whether or not AI primarily based on fragmented judicial information can reach unbiased decisions. I asked why the inventory costs are down; you simply painted a positive image! My image is of the long term; in the present day is the brief run, and it appears seemingly the market is working through the shock of R1’s existence. This famously ended up working better than different more human-guided strategies. During this section, DeepSeek-R1-Zero learns to allocate extra pondering time to an issue by reevaluating its preliminary strategy. A very intriguing phenomenon observed through the training of DeepSeek-R1-Zero is the occurrence of an "aha moment". This moment will not be solely an "aha moment" for the model but additionally for the researchers observing its behavior. It underscores the ability and wonder of reinforcement learning: relatively than explicitly teaching the mannequin on how to solve an issue, we simply present it with the correct incentives, and it autonomously develops advanced problem-fixing strategies. DeepSeek gave the mannequin a set of math, code, and logic questions, and set two reward features: one for the proper reply, and one for the right format that utilized a pondering course of.
It has the flexibility to think via an issue, producing much greater high quality outcomes, significantly in areas like coding, math, and logic (however I repeat myself). R1 is a reasoning model like OpenAI’s o1. During training, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors. Following this, we perform reasoning-oriented RL like DeepSeek-R1-Zero. This, by extension, probably has everybody nervous about Nvidia, which obviously has a giant impression on the market. In the long run, DeepSeek might change into a major player in the evolution of search know-how, especially as AI and privateness considerations continue to form the digital panorama. Individuals who want to make use of DeepSeek for more superior tasks and use APIs with this platform for coding tasks in the backend, then one should pay. This is some of the powerful affirmations but of The Bitter Lesson: you don’t need to show the AI the right way to motive, you possibly can just give it enough compute and information and it will teach itself! Think of it like studying by instance-relatively than counting on huge knowledge centers or uncooked computing energy, DeepSeek mimics the answers an professional would give in areas like astrophysics, Shakespeare, and Python coding, but in a much lighter manner.

댓글목록 0
등록된 댓글이 없습니다.