Deepseek - Choosing the Proper Strategy
페이지 정보
작성자 Willa 작성일 25-02-01 01:41 조회 5 댓글 0본문
 DeepSeek (official webpage), each Baichuan fashions, and Qianwen (Hugging Face) model refused to answer. It nearly feels like the character or post-coaching of the mannequin being shallow makes it feel like the model has more to offer than it delivers. Reproducing this isn't unimaginable and bodes nicely for a future where AI capability is distributed across more players. Innovations: The primary innovation of Stable Diffusion XL Base 1.Zero lies in its capacity to generate photographs of significantly greater resolution and clarity compared to previous models. Like many different Chinese AI fashions - Baidu's Ernie or Doubao by ByteDance - DeepSeek is educated to keep away from politically sensitive questions. Build - Tony Fadell 2024-02-24 Introduction Tony Fadell is CEO of nest (purchased by google ), and instrumental in constructing products at Apple just like the iPod and the iPhone. It’s a very succesful model, but not one that sparks as much joy when utilizing it like Claude or with tremendous polished apps like ChatGPT, so I don’t anticipate to maintain using it long term. It's extra like he's speaking about in some way taking a CoT generated by one mannequin and applying it to another, although that additionally appears nonsensical. The deepseek-coder mannequin has been upgraded to DeepSeek-Coder-V2-0614, significantly enhancing its coding capabilities.
DeepSeek (official webpage), each Baichuan fashions, and Qianwen (Hugging Face) model refused to answer. It nearly feels like the character or post-coaching of the mannequin being shallow makes it feel like the model has more to offer than it delivers. Reproducing this isn't unimaginable and bodes nicely for a future where AI capability is distributed across more players. Innovations: The primary innovation of Stable Diffusion XL Base 1.Zero lies in its capacity to generate photographs of significantly greater resolution and clarity compared to previous models. Like many different Chinese AI fashions - Baidu's Ernie or Doubao by ByteDance - DeepSeek is educated to keep away from politically sensitive questions. Build - Tony Fadell 2024-02-24 Introduction Tony Fadell is CEO of nest (purchased by google ), and instrumental in constructing products at Apple just like the iPod and the iPhone. It’s a very succesful model, but not one that sparks as much joy when utilizing it like Claude or with tremendous polished apps like ChatGPT, so I don’t anticipate to maintain using it long term. It's extra like he's speaking about in some way taking a CoT generated by one mannequin and applying it to another, although that additionally appears nonsensical. The deepseek-coder mannequin has been upgraded to DeepSeek-Coder-V2-0614, significantly enhancing its coding capabilities.
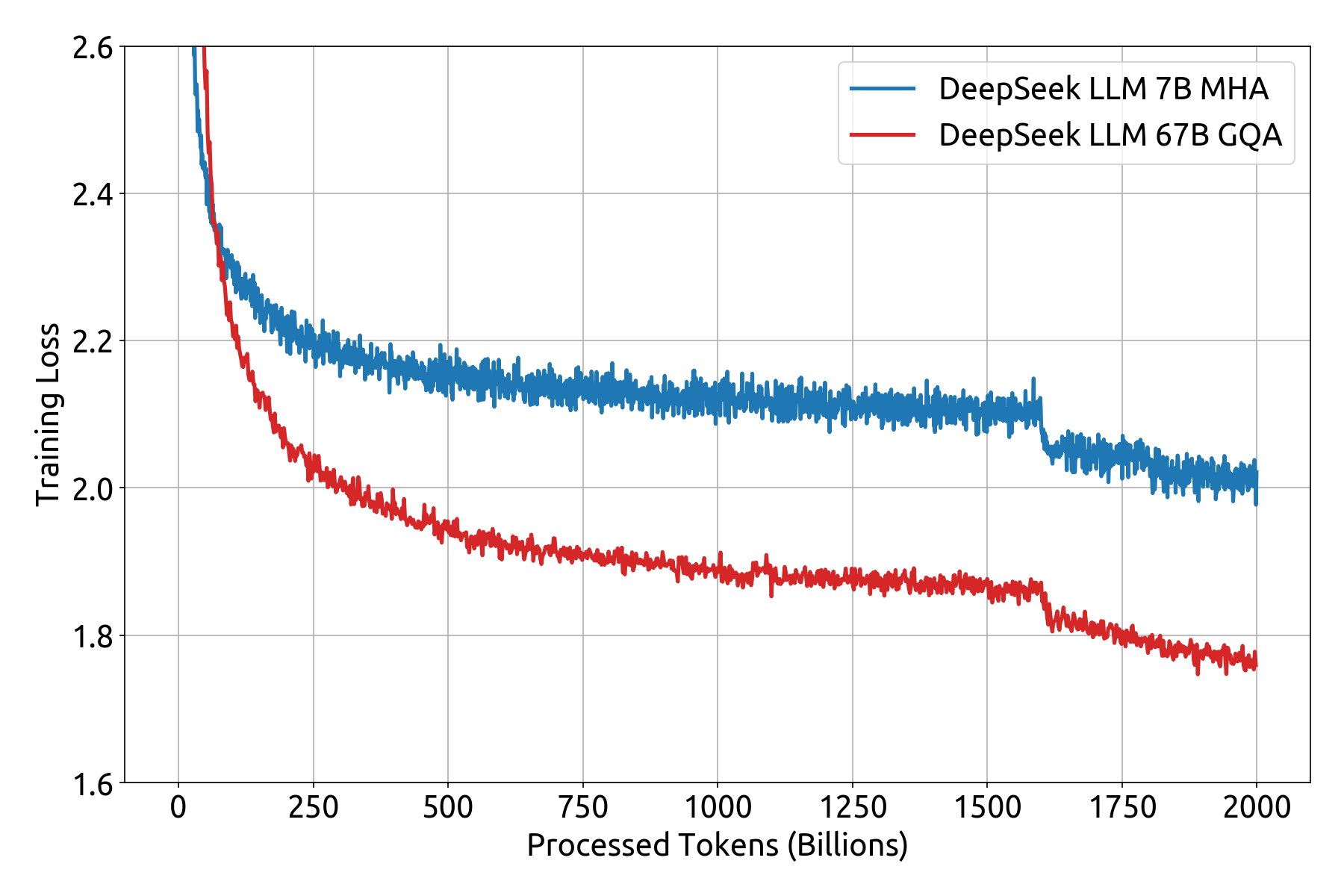
 As companies and builders search to leverage AI extra effectively, DeepSeek-AI’s latest release positions itself as a prime contender in each general-function language tasks and specialized coding functionalities. And most importantly, by displaying that it works at this scale, Prime Intellect is going to carry extra attention to this wildly vital and unoptimized part of AI research. Multi-head latent attention (MLA)2 to attenuate the reminiscence utilization of attention operators whereas maintaining modeling efficiency. The technical report shares numerous particulars on modeling and infrastructure selections that dictated the ultimate end result. Please don't hesitate to report any points or contribute ideas and code. Among the many universal and loud praise, there has been some skepticism on how a lot of this report is all novel breakthroughs, a la "did deepseek ai truly want Pipeline Parallelism" or "HPC has been doing this type of compute optimization endlessly (or also in TPU land)". After all we're performing some anthropomorphizing but the intuition right here is as effectively based as the rest.
As companies and builders search to leverage AI extra effectively, DeepSeek-AI’s latest release positions itself as a prime contender in each general-function language tasks and specialized coding functionalities. And most importantly, by displaying that it works at this scale, Prime Intellect is going to carry extra attention to this wildly vital and unoptimized part of AI research. Multi-head latent attention (MLA)2 to attenuate the reminiscence utilization of attention operators whereas maintaining modeling efficiency. The technical report shares numerous particulars on modeling and infrastructure selections that dictated the ultimate end result. Please don't hesitate to report any points or contribute ideas and code. Among the many universal and loud praise, there has been some skepticism on how a lot of this report is all novel breakthroughs, a la "did deepseek ai truly want Pipeline Parallelism" or "HPC has been doing this type of compute optimization endlessly (or also in TPU land)". After all we're performing some anthropomorphizing but the intuition right here is as effectively based as the rest.
We give you the inside scoop on what companies are doing with generative AI, from regulatory shifts to practical deployments, so you can share insights for max ROI. The put up-coaching facet is much less innovative, but offers more credence to those optimizing for online RL training as DeepSeek did this (with a type of Constitutional AI, as pioneered by Anthropic)4. By making DeepSeek-V2.5 open-source, DeepSeek-AI continues to advance the accessibility and potential of AI, cementing its position as a leader in the field of large-scale fashions. DeepSeek's optimization of restricted resources has highlighted potential limits of U.S. DeepSeek's success and performance. We're excited to announce the discharge of SGLang v0.3, which brings important efficiency enhancements and expanded support for novel model architectures. This could occur when the mannequin relies closely on the statistical patterns it has learned from the coaching knowledge, even when these patterns don't align with actual-world information or information. That is all the things from checking fundamental information to asking for suggestions on a piece of labor. Import AI runs on lattes, ramen, and feedback from readers. It’s on a case-to-case basis depending on where your affect was on the previous firm.
The $5M figure for the last coaching run should not be your foundation for how a lot frontier AI models price. This publish revisits the technical particulars of DeepSeek V3, however focuses on how finest to view the associated fee of coaching fashions at the frontier of AI and the way these costs may be altering. Many of these details were shocking and extremely unexpected - highlighting numbers that made Meta look wasteful with GPUs, which prompted many on-line AI circles to roughly freakout. Then he opened his eyes to look at his opponent. A free deepseek self-hosted copilot eliminates the necessity for expensive subscriptions or licensing fees related to hosted solutions. On 2 November 2023, DeepSeek launched its first collection of mannequin, DeepSeek-Coder, which is out there without spending a dime to each researchers and commercial customers. The researchers plan to extend DeepSeek-Prover’s knowledge to more advanced mathematical fields. We're actively working on extra optimizations to totally reproduce the outcomes from the DeepSeek paper.
If you beloved this short article as well as you wish to be given more info concerning ديب سيك generously stop by our webpage.
- 이전글 Popular Spa Treatments With Your Face
- 다음글 Discover Casino Site and the Benefits of Casino79 as Your Scam Verification Platform
댓글목록 0
등록된 댓글이 없습니다.