4 Funny Deepseek Ai News Quotes
페이지 정보
작성자 Jaclyn 작성일 25-03-02 14:49 조회 6 댓글 0본문
 The most recent entrant into the world of ChatGPT rivals is DeepSeek, a surprise startup out of China that has already effectively knocked $600 billion off of Nvidia's valuation. July 2023 by Liang Wenfeng, a graduate of Zhejiang University’s Department of Electrical Engineering and a Master of Science in Communication Engineering, who founded the hedge fund "High-Flyer" along with his enterprise companions in 2015 and has quickly risen to become the first quantitative hedge fund in China to raise more than CNY100 billion. Similarly, when choosing high k, a decrease top okay throughout training results in smaller matrix multiplications, leaving Free DeepSeek r1 computation on the desk if communication prices are massive sufficient. This strategy permits us to steadiness reminiscence effectivity and communication cost throughout large scale distributed coaching. As we scale to thousands of GPUs, the price of communication throughout units increases, slowing down coaching. Additionally, when training very giant models, the scale of checkpoints could also be very giant, resulting in very slow checkpoint add and download times. As GPUs are optimized for big-scale parallel computations, larger operations can better exploit their capabilities, resulting in increased utilization and efficiency. But what's the first objective of Deepseek, and who can profit from this platform?
The most recent entrant into the world of ChatGPT rivals is DeepSeek, a surprise startup out of China that has already effectively knocked $600 billion off of Nvidia's valuation. July 2023 by Liang Wenfeng, a graduate of Zhejiang University’s Department of Electrical Engineering and a Master of Science in Communication Engineering, who founded the hedge fund "High-Flyer" along with his enterprise companions in 2015 and has quickly risen to become the first quantitative hedge fund in China to raise more than CNY100 billion. Similarly, when choosing high k, a decrease top okay throughout training results in smaller matrix multiplications, leaving Free DeepSeek r1 computation on the desk if communication prices are massive sufficient. This strategy permits us to steadiness reminiscence effectivity and communication cost throughout large scale distributed coaching. As we scale to thousands of GPUs, the price of communication throughout units increases, slowing down coaching. Additionally, when training very giant models, the scale of checkpoints could also be very giant, resulting in very slow checkpoint add and download times. As GPUs are optimized for big-scale parallel computations, larger operations can better exploit their capabilities, resulting in increased utilization and efficiency. But what's the first objective of Deepseek, and who can profit from this platform?
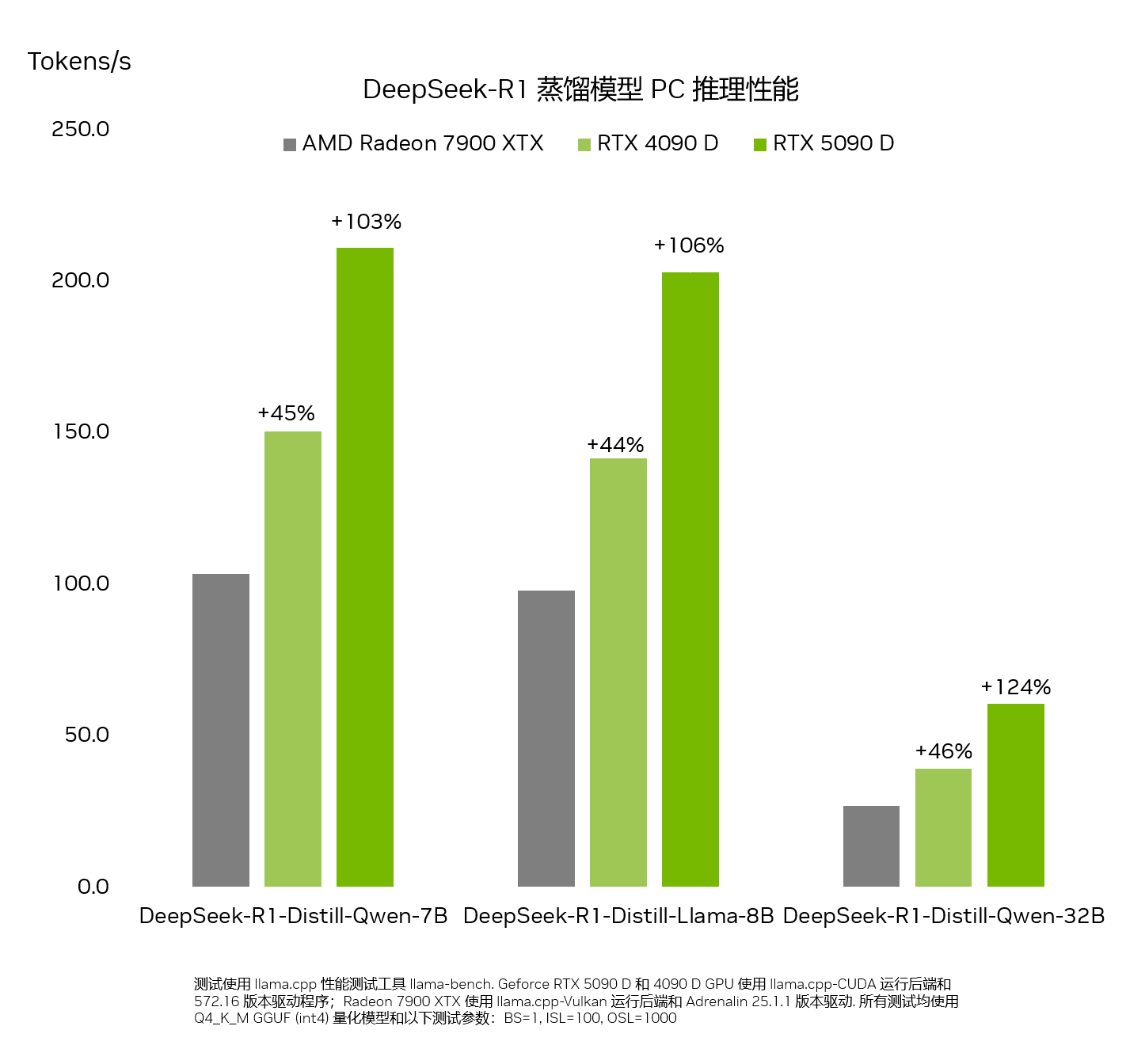 Deepseek free, a Hangzhou-based startup, has been showered with reward by Silicon Valley executives and US tech company engineers alike, who say its models DeepSeek-V3 and DeepSeek-R1 are on par with OpenAI and Meta's most superior fashions. Donald Trump called it a "wake-up call" for tech companies. We use PyTorch’s implementation of ZeRO-3, referred to as Fully Sharded Data Parallel (FSDP). Along with expert parallelism, we use knowledge parallelism for all other layers, where each GPU shops a copy of the model and optimizer and processes a special chunk of data. MegaBlocks implements a dropless MoE that avoids dropping tokens whereas using GPU kernels that maintain efficient training. We’ve integrated MegaBlocks into LLM Foundry to allow scaling MoE training to thousands of GPUs. The next number of experts permits scaling as much as larger models with out rising computational value. As a result, the capacity of a model (its total number of parameters) will be increased without proportionally growing the computational requirements.
Deepseek free, a Hangzhou-based startup, has been showered with reward by Silicon Valley executives and US tech company engineers alike, who say its models DeepSeek-V3 and DeepSeek-R1 are on par with OpenAI and Meta's most superior fashions. Donald Trump called it a "wake-up call" for tech companies. We use PyTorch’s implementation of ZeRO-3, referred to as Fully Sharded Data Parallel (FSDP). Along with expert parallelism, we use knowledge parallelism for all other layers, where each GPU shops a copy of the model and optimizer and processes a special chunk of data. MegaBlocks implements a dropless MoE that avoids dropping tokens whereas using GPU kernels that maintain efficient training. We’ve integrated MegaBlocks into LLM Foundry to allow scaling MoE training to thousands of GPUs. The next number of experts permits scaling as much as larger models with out rising computational value. As a result, the capacity of a model (its total number of parameters) will be increased without proportionally growing the computational requirements.
A extra in depth rationalization of the advantages of larger matrix multiplications may be discovered here. Compared to dense models, MoEs present more efficient coaching for a given compute finances. PyTorch Distributed Checkpoint ensures the model’s state could be saved and restored accurately throughout all nodes within the coaching cluster in parallel, regardless of any changes within the cluster’s composition because of node failures or additions. However, if all tokens at all times go to the identical subset of specialists, training becomes inefficient and the opposite specialists find yourself undertrained. The variety of specialists and the way consultants are chosen depends on the implementation of the gating network, but a typical method is high ok. Fault tolerance is essential for ensuring that LLMs can be educated reliably over prolonged durations, especially in distributed environments the place node failures are frequent. For developers, Qwen2.5-Max can also be accessed through the Alibaba Cloud Model Studio API. The number of specialists chosen must be balanced with the inference prices of serving the model since the complete mannequin needs to be loaded in reminiscence.
When utilizing a MoE in LLMs, the dense feed ahead layer is replaced by a MoE layer which consists of a gating network and a variety of experts (Figure 1, Subfigure D). To mitigate this difficulty whereas maintaining the advantages of FSDP, we make the most of Hybrid Sharded Data Parallel (HSDP) to shard the mannequin and optimizer across a set number of GPUs and replicate this a number of occasions to totally utilize the cluster. We will then build a system mesh on prime of this format, which lets us succinctly describe the parallelism throughout your entire cluster. We first manually place experts on totally different GPUs, sometimes sharding throughout a node to ensure we are able to leverage NVLink for quick GPU communication once we route tokens. After every GPU has accomplished a forward and backward go, gradients are accumulated across GPUs for a global mannequin update. With HSDP, a further all reduce operation is needed within the backward go to sync gradients throughout replicas. When a failure happens, the system can resume from the final saved state fairly than beginning over. In this blog submit, we’ll talk about how we scale to over three thousand GPUs using PyTorch Distributed and MegaBlocks, an efficient open-supply MoE implementation in PyTorch.
If you have any concerns with regards to where by and how to use Free DeepSeek Ai Chat, you can get in touch with us at our own site.
댓글목록 0
등록된 댓글이 없습니다.